Query Engine
介绍
GreptimeDB 的查询引擎是基于Apache DataFusion(属于Apache Arrow的子项目)构建的,它是一个用 Rust 编写的出色的查询引擎。它提供了一整套功能齐全的组件,从逻辑计划、物理计划到执行运行时。下面将解释每个组件如何被整合在一起,以及在执行过程中它们的位置。
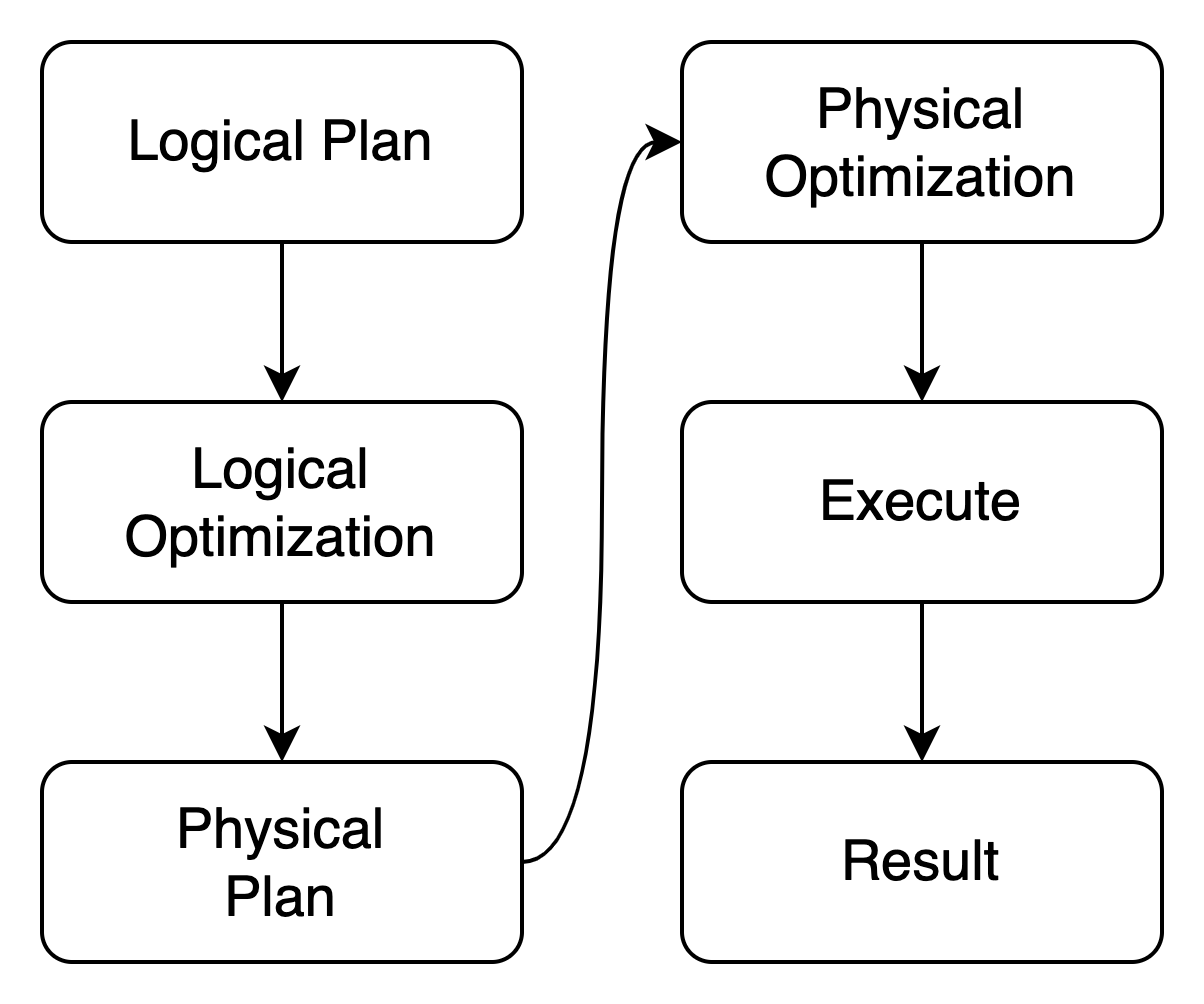
入口点是逻辑计划,它被用作查询或执行逻辑等的通用中间表示。逻辑计划的两个主要来源是:1. 用户查询,例如通过 SQL 解析器和规划器的 SQL;2. Frontend 的分布式查询,这将在下一节中详细解释。
接下来是物理计划,或称执行计划。与包含所有逻辑计划变体(除特殊扩展计划节点外)的大型枚举的逻辑计划不同,物理计划实际上是一个定义了在执行过程中调用的一组方法的特性。所有数据处理逻辑都包装在实现该特性的相应结构中。它们是对数据执行的实际操作,如聚合器 MIN 或 AVG ,以及表扫描 SELECT ... FROM。
优化阶段通过转换逻辑计划和物理计划来提高执行性能,现在全部基于规则。它也被称为“基于规则的优化”。一些规则是 DataFusion 原生的,其他一些是在 GreptimeDB 中自定义的。在未来,我们计划添加更多规则,并利用数据统计进行基于成本的优化 (CBO)。
��最后一个阶段"执行"是一个动词,代表从存储读取数据、进行计算并生成预期结果的过程。虽然它比之前提到的概念更抽象,但你可以简单地将它想象为执行一个 Rust 异步函数,并且它确实是一个异步流。
当你想知道 SQL 是如何通过逻辑计划或物理计划中表示时,EXPLAIN [VERBOSE] <SQL> 是非常有用的。
数据表示
GreptimeDB 使用 Apache Arrow作为内存中的数据表示格式。它是面向列的,以跨平台格式,也包含许多高性能的基础操作。这些特性使得在许多不同的环境中共享数据和实现计算逻辑变得容易。
索引
在时序数据中,有两个重要的维度:时间戳和标签列(或者类似于关系数据库中的主键)。GreptimeDB 将数据分组到时间桶中,因此能在非常低的成本下定位和提取预期时间范围内的数据。GreptimeDB 中主要使用的持久文件格式 Apache Parquet 提供了多级索引和过滤器,使得在查询过程中很容易修剪数据。在未来,我们将更多地利用这个特性,并开发我们的分离索引来处理更复杂的用例。
拓展性
在 GreptimeDB 中扩展操作非常简单。有两种方法可以做到:1. 通过 Python Coprocessor 接口;2. 像 这样 实现你的算子。