基于单集群跨区域部署的 DR 解决方案
GreptimeDB DR 的工作原理
GreptimeDB 非常适合跨区域灾难恢复。GreptimeDB 提供了量身定制的解决方案,以满足不同区域特征和业务需求的多样化要求。
GreptimeDB 资源管理涉及 Availability Zones(AZ)的概念。一个 AZ 是一个逻辑上的灾难恢复单元。 它可以是数据中心(DC),也可以是 DC 的一个分区,这取决于你具体的 DC 条件和部署设计。
在跨区域灾难恢复解决方案中,一个 GreptimeDB 区域是一个城市。当两个 DC 在同一区域且其中一个 DC 不可用时,另一个 DC 可以接管不可用 DC 的服务。这是一种本地化策略。
在了解每个 DR 解决方案的细节之前,有必要先了解以下知识:
- Remote wal 组件的 DR 解决方案也非常重要。本质上,它构成了整个 DR 解决方案的基础。因此,对于每个 GreptimeDB 的 DR 解决方案,我们将在图中展示 remote wal 组件。目前,GreptimeDB 默认使用基于 Kafka 实现的 remote wal 组件,将来会提供其他实现;然而,在部署上不会有显著差异。
- GreptimeDB 表:每张表可以根据一定范围划分为多个分区,每个分区可能分布在不同的数据节点上。在写入或查询时,会根据相应的路由规则调用到指定的数据节点。一张表的分区可能如下所示:
Table name: T1
Table partition count: 4
T1-1
T1-2
T1-3
T1-4
Table name: T2
Table partition count: 3
T2-1
T2-2
T2-3
元数据跨两个区域,数据在同一区域
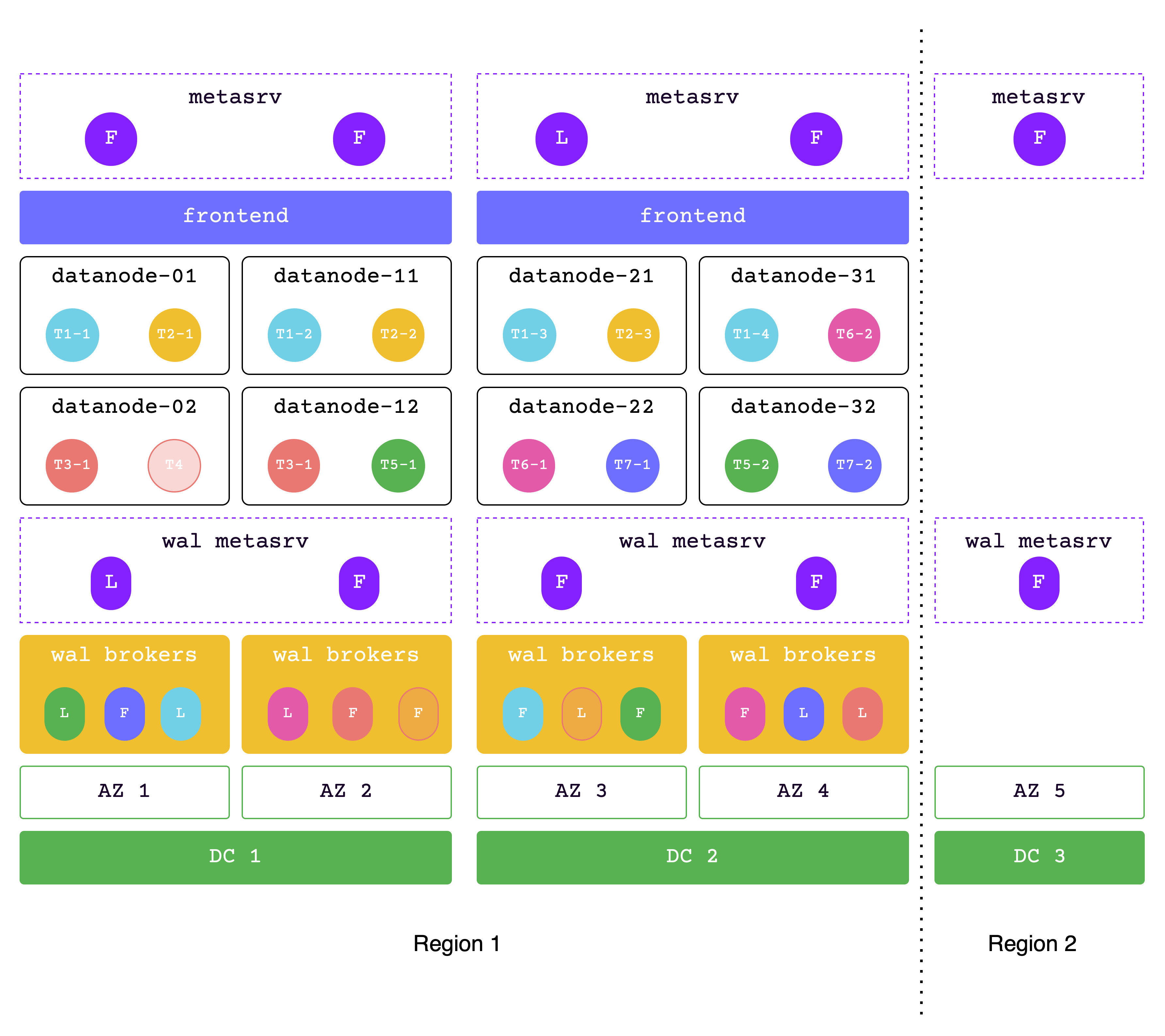
在此解决方案中,数据位于一个区域(2 个 DC),而元数据跨越两个区域。
DC1 和 DC2 一起用于处理读写服务,而位于第二区域的 DC3 是用来满足多数派协议的副本。这种架构也被称为 “2-2-1” 解决方案。
在极端情况下,DC1 和 DC2 都必须能够处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2ms
- 两个区域间延迟为 30ms
支持高可用性级别:
- 单个 AZ 不可用时性能相同
- 单个 DC 不可用时性能几乎相同
如果您想要一个区域级别的灾难恢复解决方案,可以更进一步,在 DC3 上提供读写服务。因此,下一个解决方案是:
数据跨两个区域
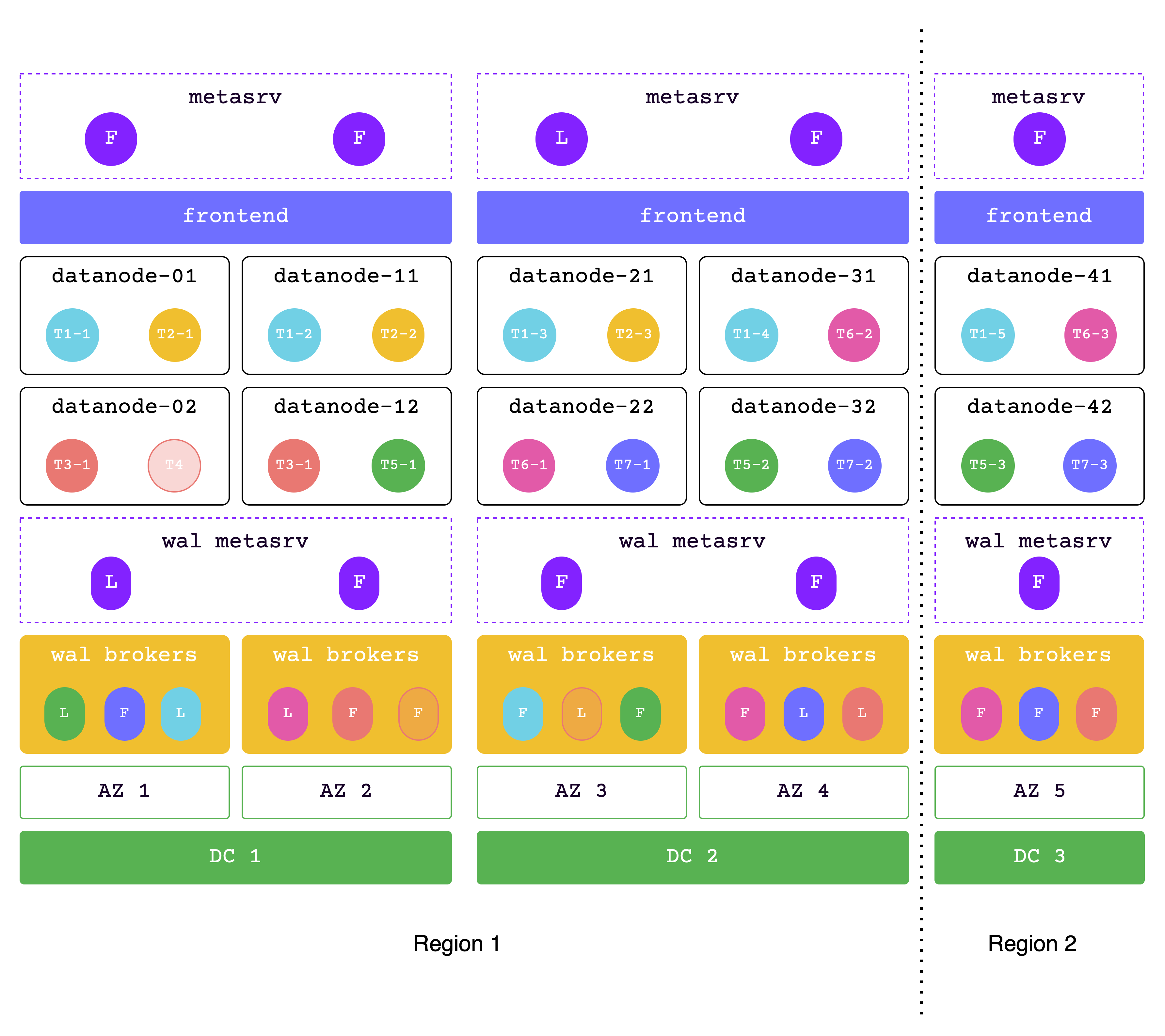
在此解决方案中,数据跨越两个区域。
每个数据中心必须能够在极端情况下处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2 毫秒
- 两个区域间延迟为 30 毫秒
支持高可用性级别:
- 单个可用区不可用时性能不变
- 单个数据中心不可用时性能下降
如果无法容忍单个数据中心故障导致的性能下降,请考虑升级到五个数据中心和三个区域的解决方案。
元数据跨三个区域,数据跨两个区域
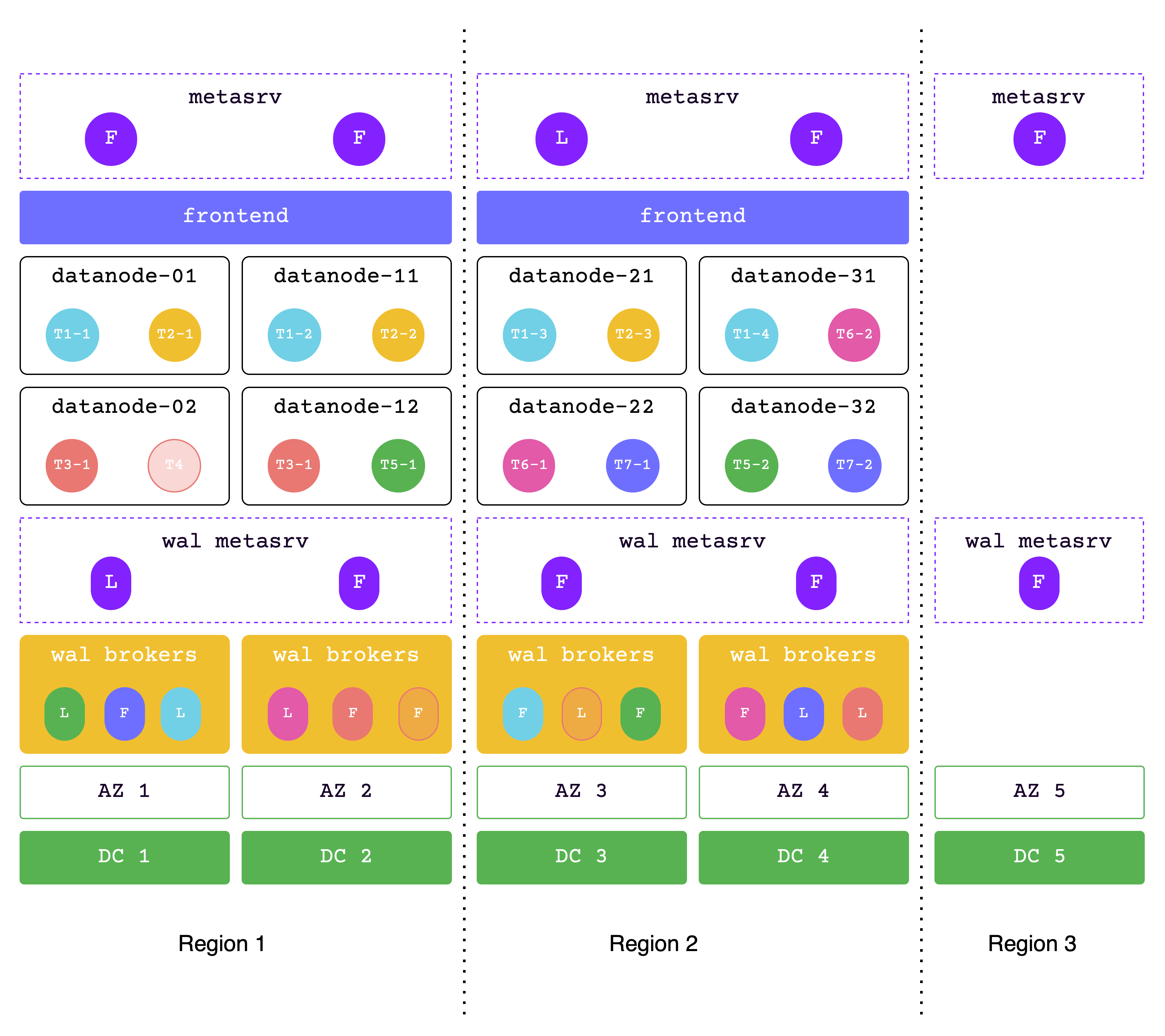
在此解决方案中,数据跨越两个区域,而元数据跨越三个区域。
Region1 和 Region2 一起用于处理读写服务,而 Region3 是一个副本,用于满足多数派协议。这种架构也被称为 “2-2-1” 解决方案。
两个相邻的区域中的每一个都必须能够在极端情况下处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2ms
- 两个相邻区域之间延迟为 7ms
- 两个远距离区域之间延迟为 30ms
支持高可用性级别:
- 单一 AZ 不可用时性能不变
- 单一 DC 不可用时性能不变
- 单一区域(城市)不可用时性能略有下降
您可以更进一步,在三个区域上提供读写服务。因此,下一个解决方案是: (此解决方案可能具有更高的延迟,如果无法接受,则不推荐。)
数据跨三个区域
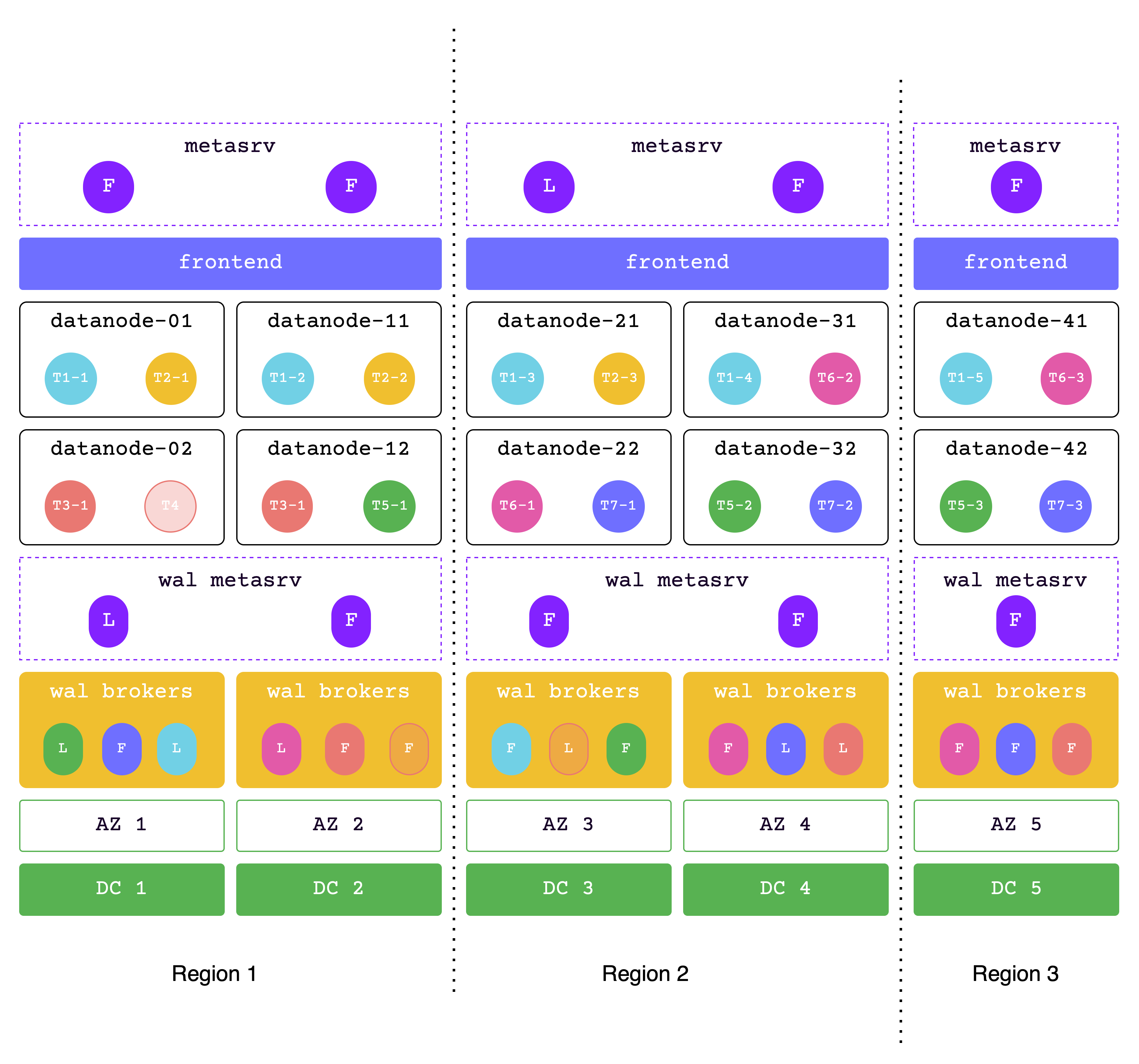
在此解决方案中,数据跨越三个区域。
如果一个区域发生故障,其他两个区域必须能够处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2 毫秒
- 相邻两个区域之间的延迟为 7 毫秒
- 两个远距离区域之间的延迟为 30 毫秒
支持高可用性级别:
- 单个 AZ 不可用时性能不变
- 单个 DC 不可用时性能不变
- 单个区域(城市)不可用时性能下降
解决方案比较
上述解决方案的目标是在中大型场景中满足高可用性和可靠性的要求。然而,在具体实施过程中,每种解决方案的成本和效果可能会有所不同。下表对每种解决方案进行了比较,以帮助你根据具体场景、需求和成本进行最终选择。
以下是内容格式化为表格:
| 解决方案 | 延迟 | 高可用性 |
|---|---|---|
| 元数据跨两个区域,数据在同一区域 | - 同一区域内延迟 2 毫秒 - 两个区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变 - 单个 DC 不可用时性能几乎不变 |
| 数据跨两个区域 | - 同一区域内延迟 2 毫秒 - 两个区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变 - 单个 DC 不可用时性能下降 |
| 元数据跨三个区域,数据跨两个区域 | - 同一区域内延迟 2 毫秒 - 相邻两个区域间延迟 7 毫秒 - 两个远距离的区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变 - 单个 DC 不可用时性能不变 - 单一区域(城市)不可用时,性能略有下降 |
| 数据跨三个区域 | - 同一区域内延迟 2 毫秒 - 相邻两个区域间延迟 7 毫秒 - 两个远距离的区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变 - 单个 DC 不可用时性能不变 - 单一区域(城市)不可用时, 性能下降 |